

Multi-tenancy without a database per account
Row-level security in Postgres handled tenant isolation. Async queues absorbed background failures. Webhooks survived third-party outages. Here is how each decision was made and what it cost.
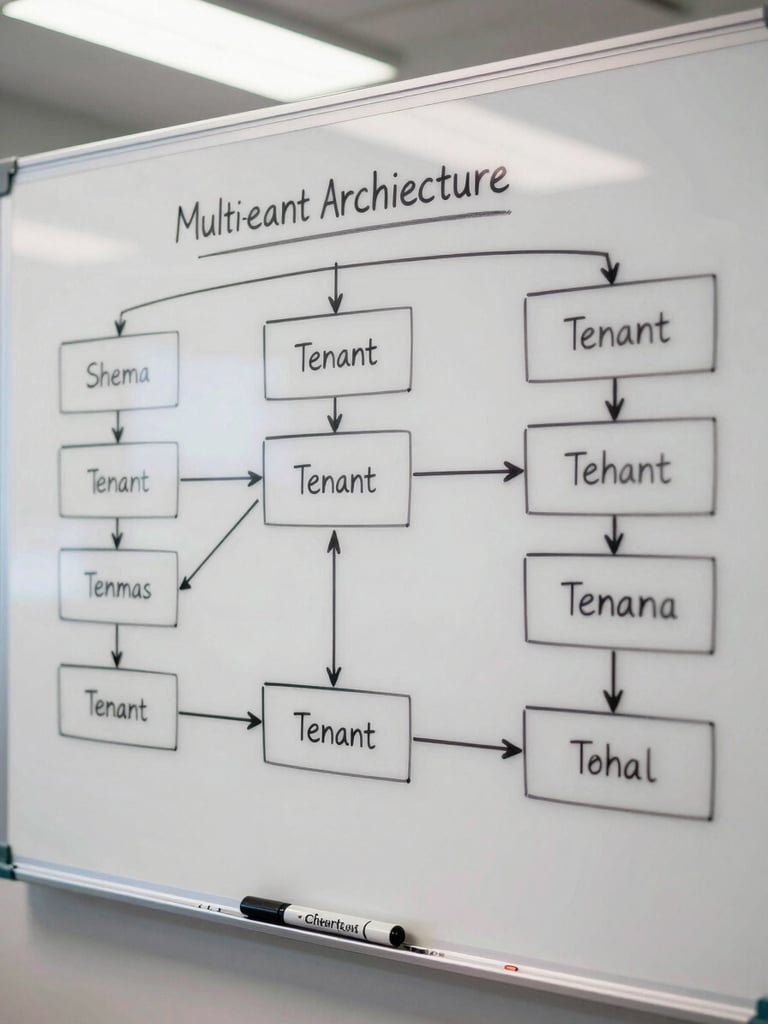
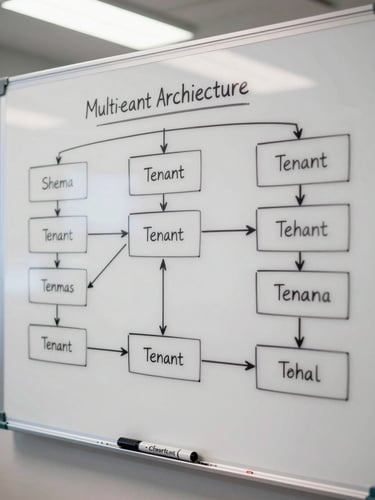
Shared schema, isolated tenants, no heroics at scale
The client ran 400-plus accounts on a single application. A per-tenant database model would have made ops unsustainable by account 50. The requirement: full data isolation with none of the provisioning overhead.
The second constraint was reliability. Background jobs — report generation, email dispatch, third-party syncs — had to survive failures silently. Users could not see queue depth or retry state.



RLS, async queues, and webhook resilience
Row-level security in Postgres
Every table carries a tenant_id column. RLS policies enforce that queries from application connections never touch rows outside the active tenant context. No application-layer filtering required — the database rejects the query.
The trade-off: RLS adds a policy evaluation step to every read. We benchmarked it at under 2ms overhead on a p99 basis. For this workload that was acceptable; for analytical queries over the full dataset it was not, so those run through a separate read replica with elevated roles.
Async job queue with retry logic
Background tasks run through a Postgres-backed queue rather than an in-process scheduler. Each job records attempt count and last-error. Failures retry with exponential backoff; jobs that exhaust retries land in a dead-letter table, not in a user-visible error state.
The queue is in Postgres deliberately. It keeps the operational surface small: no separate broker to provision, monitor, or restart. The cost is that high-throughput fan-out (tens of thousands of jobs per minute) would require a dedicated broker. This client's volume did not require it.
Webhook reliability layer
Third-party APIs go down. The webhook layer treats every outbound call as unreliable by default: requests are enqueued, dispatched with a configurable timeout, and retried on non-2xx responses using exponential backoff with jitter.
Events that fail after the maximum retry window move to a dead-letter queue with a full request and response log. Operators can inspect, replay, or discard them. No event is silently dropped; the audit trail is complete by design.
Numbers from the first six months of operation
Under 2ms
99.97% job completion
Zero silent drops
p99 overhead added by row-level security policy evaluation across all tenant-scoped read queries in steady-state traffic.
Background jobs completed or dead-lettered without user-visible failure over the first 180 days across all tenant accounts.
Every webhook event that exhausted retries landed in the dead-letter queue with a full request and response log. None discarded without audit record.
Building a SaaS product and weighing the same trade-offs? We document every architectural decision before we ship a line of code.